Optimizing 6502 Instruction Fetches
Background on Emulation Performance
Emulation—the complete simulation of a digital circuit using software—is known to run exponentially slower compared to the circuit it emulates. This is because of the huge abstraction layer between the emulator and the hardware of your computer, so you have to jump through many hoops to implement behavior that is trivial to do directly with hardware.
For example, modern CPUs implement instruction pipelining when executing an instruction, which is a way of running other instructions in parts of the CPU that aren't being utilized by the current instruction. This looks something like the following:
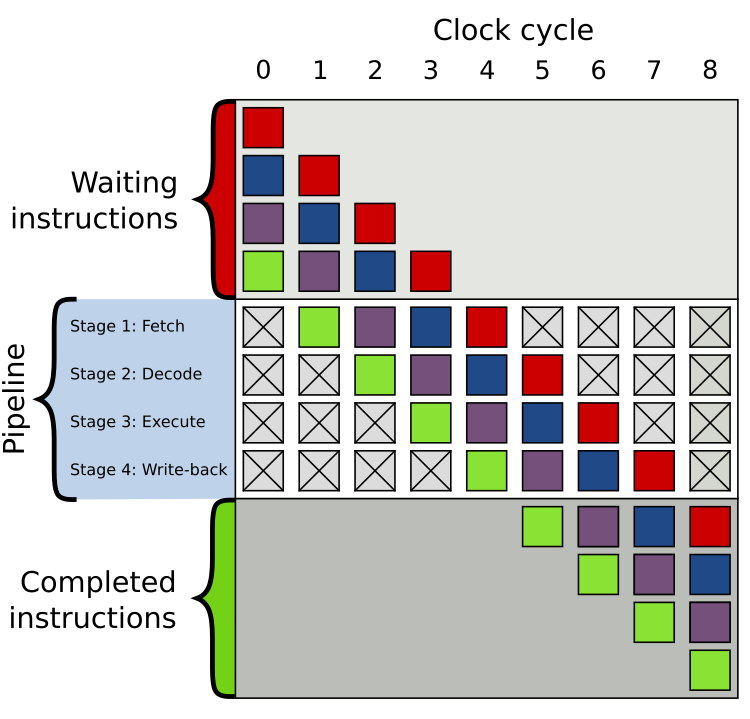
The first instruction is initially at the fetch stage, and all other instructions are waiting. Then, once the first instruction goes to the decode stage, the next instruction can go to the fetch stage as it is currently unoccupied. The remaining instructions run similarly, significantly reducing execution time. The reason this works is that CPU instructions are fairly standardized. They all follow a sequence of simple, standalone instructions that can be completed in a certain number of clock cycles, and different parts of a CPU are optimized to handle these operations:
- Fetch - Get the next instruction byte from memory
- Decode - Figure out what instruction this byte corresponds to
- Execute - Execute the required instruction
- (Optional) Write-back - Write the result of the execution to memory
This behavior is baked into the hardware, so there is no need to program or configure it. When emulating, however, all of these optimizations relating to instruction execution are left to the developer. For the 6502 CPU (the CPU found inside the Nintendo Entertainment System, or NES), however, such optimizations aren't even necessary—emulating the 6502's ~2 Mhz clock would be a breeze for any modern computer running at several gigahertz.
Regardless, I wanted my NES emulator to be able to run on slower chips and microcontrollers. Moreover, I wanted my emulator to be cycle accurate. This just means that the emulator simulates every clock cycle of the given circuit faithfully, as it would've ran in hardware. For example, to add two numbers, you would need the following (rough) steps on any CPU, where each one would take a single clock cycle:
- Get the first number
- Get the second number
- Add the two numbers
- Store the result
You can easily spend one false clock cycle to execute this entire instruction since, again, modern computers are very fast, then waste the following three cycles to match up with the hardware. The downside of this is that some games built for the NES depend on per-cycle behavior, so you would not be able to play them bug-free.
Cycle accuracy makes emulation even more expensive, so optimizations became necessary for my emulator. This article describes some of the steps I took to optimize the instruction fetch and decode stages of my NES emulator's 6502 CPU while maintaining cycle accuracy.
Attempt #1. Naive Approach: One Giant Switch Statement™
My first implementation of the 6502 CPU used the naive approach I learned about and used in my CHIP-8 emulator: one giant switch statement. It worked by reading an instruction opcode (the byte of data that corresponds to some instruction) from a ROM file, passing that into a switch statement, then handling what each instruction should do for each valid case.
// fetch -> decode sequence
let opcode: u8 = self.mem_read(self.pc);
match(opcode)
{
0x00 => {},
0x01 => {},
0x02 => {},
.
.
.
0xFF => {},
}
This has a number of issues, the most obvious being that it is terribly complicated code, especially if I wanted to apply the same idea for an even larger CPU like any x86 processor with several thousand instructions. Besides qualitative gripes, however, a switch statement is a conditional expression, and conditional expressions can be slow due to branch prediction, even if this approach technically has an worst case time complexity. Thus, any changes should attempt to keep the code clean while avoiding conditionals for speedup.
Attempt #2. Map-based Lookup Tables: Dissapointing Results
My next attempt was a map-based lookup table. Opcodes are fetched from memory and decoded into an instruction, so it only makes sense to consider a mapping of opcode to instruction handler functions. The approach was to first write out functions implementing the opcodes, then perform a single operation to construct the map at runtime, where is the number of opcodes. To avoid conditionals, this required writing out an array of instructions.
// Addressing mode functions
fn addr_abs(subcycle: u8) -> bool {}
fn addr_rel(subcycle: u8) -> bool {}
.
.
.
fn addr_iny(subcycle: u8) -> bool {}
// Instruction implementation functions
fn bpl(subcycle: u8) -> bool {}
fn jmp(subcycle: u8) -> bool {}
.
.
.
fn and(subcycle: u8) -> bool {}
// Map building
struct Instruction
{
opcode: u8,
addressing_mode: fn(subcycle: u8) -> bool,
instruction_handler: fn(subcycle: u8) -> bool
}
let instructions: [Instruction; 256] = [
Instruction {
opcode: 0x10,
addressing_mode: addr_rel,
instruction_handler: bpl,
},
Instruction {
opcode: 0x4C,
addressing_mode: addr_abs,
instruction_handler: jmp,
},
.
.
.
Instruction {
opcode: 0x31,
addressing_mode: addr_iny,
instruction_handler: and,
},
];
use std::collections::HashMap;
let mut opcode_instruction_map: HashMap<u8, Instruction> = HashMap::new();
for instruction in instructions:
{
opcode_instruction_map.insert(instruction.opcode, instruction);
}
Then, for the replacement of the previous switch statement,
// fetch -> decode sequence
let opcode: u8 = self.mem_read(self.pc);
let instruction: Option<&Instruction> = opcode_instruction_map.get(opcode);
Each instruction fetch now runs in average time, but has a worst case complexity of where is the number of opcodes. This is due to how hash map implementations work, as collisions between keys increase the lookup time. I hoped this approach would be better since the nature of the fetch-decode sequence implies a map-based implementation, but the time complexity is worse than the switch statement in the worst case and there is still a hidden conditional in the map implementation to check for the required key.
Attempt #3. List-based Lookup Tables: Final Version?
I got the idea for the (potentially final) implementation while going through my map-based implementation. While building the opcode array, it hit me that the instruction opcode being a single byte limited it to 256 possibilities. Thus, it suffices to store all instructions in a 256-entry array and use the opcode to index into it! Not all of the 256 instructions are officially defined, the missing ones labeled illegal opcodes. However, some NES games do use these opcodes, so you may implement them or leave that entry of the array as a None type. That way, you can have an opcode to instruction mapping implicitly, without incurring the overhead of a hash map.
// List building
let instructions: [Option<Instruction>; 256] = [
Some(Instruction {
opcode: 0x00,
addressing_mode: addr_imp,
instruction_handler: brk,
}),
Some(Instruction {
opcode: 0x01,
addressing_mode: addr_inx,
instruction_handler: ora,
}),
.
.
.
// Example of an illegal opcode
Some(Instruction {
opcode: 0xFF,
addressing_mode: addr_abx,
instruction_handler: isc,
}),
];
Then, for the replacement of the map-based fetch,
let opcode: u8 = self.mem_read(self.pc);
let instruction: Option<Instruction> = instructions[opcode];
This implementation is the cleanest in my opinion, requiring only the definitions of modular instruction handler functions and building an array of those instructions. While writing out the array is somewhat tedious, it can be programmatically generated due to the similarities shared by the instructions subcycles. Moreover, indexing into an array is an time operation, and there are no conditionals anywhere.
Conclusion and Future Ideas
I am happy with attempt 3 and will probably stop here, but for processors with more instructions than the 6502, it would be interesting to look into the programmatic generation of instructions, perhaps even at runtime (see here for a discussion). The CPU of my emulator is more than fast enough for now, and I can actually read the code without scanning through hundreds of lines of switch cases. Any further optimizations should be concerned with the PPU's rendering pipeline, the more complex side of NES emulation.
That's all for this article, but be sure to check out my other posts for interesting reads on emulation, performance optimizations, and system design.